GPT-5.5 Aims to Smooth Out the Experience Rather Than Reinvent It

Six weeks. That’s the gap between GPT-5.4 and GPT-5.5. Not a development cycle — six weeks. Anyone tracking the pace of AI integration across consumer products in 2026 reads that rhythm before a single benchmark number lands. GPT-5.5 is real, the gains are real, and for the workloads OpenAI tuned it toward — agentic coding, computer use, multi-step document tasks — it outperforms GPT-5.4 in ways you can measure. What doesn’t hold as cleanly is the “new class of intelligence” framing that accompanied the launch. This is a well-executed refinement arriving at a moment when the market is absorbing AI faster than it can evaluate it. Refinement might be exactly what’s needed right now. It’s just a harder story to tell.
- GPT-5.5 is the first fully retrained base model since GPT-4.5 — versions 5.1 through 5.4 were all iterative refinements on the same underlying weights
- Token efficiency is the practical headline: OpenAI reports 40% fewer tokens for the same Codex tasks compared to GPT-5.4, which may offset the 2× output price increase for high-volume pipelines
- Claude Opus 4.7 still leads GPT-5.5 on 6 of 10 shared benchmarks, including SWE-bench Pro (64.3% vs 58.6%) and MCP Atlas — the leads cluster by workload, not by overall quality
- The strongest gains — Terminal-Bench 2.0 at 82.7% vs 69.4% for Opus 4.7, and enterprise-grade hallucination resistance — are real and worth naming without overstating them
Last updated: 2026-04-25 · Sources linked inline
GPT-5.5 delivers real improvements in token efficiency, agentic task completion, and hallucination resistance at the enterprise level. It does not represent the architectural overhaul the “new class of intelligence” language implies. The question worth answering before you change your API configuration — or your opinion of OpenAI’s current position — is whether the gains match the 2× increase on output token pricing.
Contents
The Conventional Wisdom (and Why It’s Incomplete)
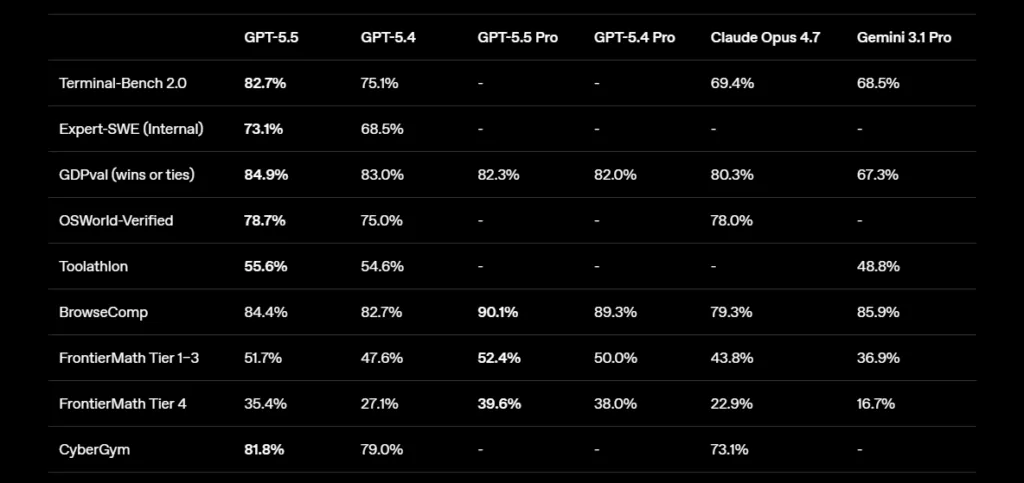
The prevailing read across tech media is straightforward: OpenAI fought back and won. The headline benchmark numbers support this — 82.7% on Terminal-Bench 2.0 against Claude Opus 4.7’s 69.4%, state-of-the-art results across 14 of the benchmarks in OpenAI’s published system card, and Greg Brockman describing it as “a new class of intelligence” during the press briefing. That phrase circulated within hours.
The problem is what that frame papers over. According to analyses by VentureBeat and reporting from Lushbinary drawing on OpenAI’s own materials, GPT-5.1 through 5.4 were all iterative improvements on the original GPT-5 base weights — not new models in any architecturally meaningful sense. GPT-5.5 is the first fully retrained foundation since GPT-4.5. That’s the actual headline. It means every model labeled GPT-5.x before April 23 was essentially fine-tuning layered on a two-year-old core. The 5.5 number is finally earned.
Framing this as a competitive comeback obscures a more specific question: what did a full retraining run actually change? The answer is workload-specific, verifiable, and not what the marketing emphasizes.
The Release Cadence Tells the Real Story
Seven Weeks Is a Sprint, Not a Development Cycle
Claude Opus 4.7 shipped April 16. GPT-5.5 shipped April 23. Seven days apart, both claiming the current frontier. The seven-week gap from GPT-5.4 to GPT-5.5 tells you this model was well into training before Anthropic’s release landed. OpenAI didn’t respond to Opus 4.7; both labs were running parallel development tracks that happened to surface in the same week.
That matters for how you read the competitive framing. Launches at the frontier are staged to look like responses. They almost never are — training runs take months, not days. What you’re seeing is PR timing, not evidence that one lab outmaneuvered the other within a week.
The “First Full Retrain Since GPT-4.5” Admission Is Buried, But Important
OpenAI’s launch post describes GPT-5.5 as a step toward “a new way of getting work done on a computer.” What received less attention: this is the first time the underlying base was retrained since GPT-4.5. Every version between 5.1 and 5.4 built on the same foundation through fine-tuning and reinforcement learning — a legitimate and productive engineering path, but not the architecture story the version numbering implied.
GPT-5.5 deserves evaluation as a genuine new foundation. That’s a higher bar than “the sixth step in a series.” On that higher bar, the results are good. Not transformative. Good.
Efficiency Is the Capability That Actually Changed
40% Fewer Tokens Is Not a Small Number
OpenAI reports that GPT-5.5 completes the same Codex tasks using approximately 40% fewer tokens than GPT-5.4. Per-token latency matches GPT-5.4 despite the higher capability level — a hardware-software co-design achievement on NVIDIA GB200 and GB300 NVL72 systems. Both of these numbers matter more than the benchmark tables for anyone running agents at scale.
Consider the cost math at 100 million output tokens per month. GPT-5.5 standard at $30 per million output tokens costs $3,000. Claude Opus 4.7 at $25 costs $2,500. On list price, GPT-5.5 is 20% more on output. If the 40% token reduction claim holds in your workloads — and third-party validation is still early — GPT-5.5 completes the same tasks using 60 million tokens, bringing the effective cost to $1,800. That math inverts the price comparison entirely. It also needs real workload testing before anyone treats it as settled.
For ChatGPT Subscribers, the Gains Are Already Visible
Unlike API developers, ChatGPT Plus, Pro, Business, and Enterprise users got GPT-5.5 the day it launched. The immediately tangible change — what early testers from Ramp and BNY reported — is the model’s ability to handle messy, multi-part instructions without requiring step-by-step scaffolding. Bank of New York’s CIO described a “step change” in hallucination resistance to Fortune, noting that accuracy at the level GPT-5.5 is reaching directly enables scaling their 220+ active AI use cases in a regulated environment.
That’s the kind of improvement that doesn’t land cleanly in benchmark tables but shows up in production workflows where wrong answers carry real cost — the same context in which AI-powered tools are being integrated directly into security and fraud detection. Accuracy is the prerequisite for trust. If GPT-5.5 moved that needle for a major financial institution, the model earned its number.
The Agentic Label Hides One Unresolved Tension
“Computer Use” Still Meant “ChatGPT Interface” for Most Early Testers
OpenAI positions GPT-5.5 as a model built for agentic work — tasks where the AI plans, executes across tools, checks its results, and iterates without continuous human prompting. The benchmarks here are strong: 78.7% on OSWorld-Verified, 82.7% on Terminal-Bench 2.0. OpenAI Chief Research Officer Mark Chen described GPT-5.5 as “meaningfully better” at navigating computer work than its predecessors.
Every early testimonial published in the 24 hours following launch — the Ramp engineer case study, the Nvidia partnership claims, the BNY findings — came through the ChatGPT or Codex interface, not custom agent pipelines with tool calls and system prompts. The API arrived the next day after what OpenAI described as additional cybersecurity guardrail review. Independent third-party benchmarks on API-level tool-call reliability are not yet in.
That doesn’t invalidate the results. The API is available now. But the strongest agentic claims are still waiting for the verification layer that enterprise developers actually care about.
The Counter-Argument (and Why It’s Not Wrong)
The strongest case against calling this a refinement: Terminal-Bench 2.0 at 82.7% is a 13-point lead over Claude Opus 4.7’s 69.4%, and that benchmark specifically tests real command-line workflows — planning, iteration, and tool coordination in a sandboxed terminal. A 13-point margin on a real-world-adjacent benchmark is not cosmetic.
There’s also the omnimodal architecture question. GPT-5.5 processes text, images, audio, and video in a single unified system rather than routing between specialized sub-models. That’s a genuine structural change — not marketing language — and it’s the kind of architectural decision that compounds over subsequent fine-tuning runs. The foundation it’s built on matters for what comes after it, not just for what it does now.
And the hallucination resistance finding from BNY is worth sitting with. If it generalizes beyond one financial institution’s workflow, that’s the single most commercially relevant quality improvement OpenAI could have made. Hallucination is the primary blocker for deploying AI agents in high-stakes environments. A step change there — if it holds across varied workloads — matters more than any benchmark table.
The position here isn’t that GPT-5.5 didn’t improve. It’s that the magnitude of the improvement, in context, matches refinement rather than reinvention.
What the Data and Early Testers Actually Say
Ten benchmarks appear in published materials from both Anthropic and OpenAI, allowing a direct comparison on shared ground. Claude Opus 4.7 leads on six: SWE-bench Pro (64.3% vs 58.6%), Humanity’s Last Exam with and without tools, GPQA Diamond, MCP Atlas, and FinanceAgent v1.1. GPT-5.5 leads on four: Terminal-Bench 2.0, BrowseComp, OSWorld-Verified, and CyberGym. LLM Stats’ independent analysis describes the pattern plainly: Opus 4.7’s leads cluster on reasoning-heavy and code-review-grade tasks; GPT-5.5’s leads cluster on long-running tool use and shell-driven automation.
One finding from Artificial Analysis is worth pulling out: GPT-5.5 at medium effort matched Claude Opus 4.7 at maximum effort on their aggregate coding index, at a lower compute cost per task. That’s the token efficiency argument made concrete — not just fewer tokens, but fewer tokens while matching or exceeding the competition at a given quality level. The broader picture of AI accountability and enterprise trust — including the legal questions still being worked through across the industry — is the context in which both models are being adopted, and it shapes how much enterprise buyers weigh hallucination resistance versus benchmark wins.
The benchmark headline — 14 benchmarks where GPT-5.5 leads versus 4 for Opus 4.7 — obscures the workload split. Neither model holds a general lead. Which one is right depends entirely on what you’re building.
What This Means for You
If you use ChatGPT Plus, Pro, Business, or Enterprise, GPT-5.5 is already running in your account. For document creation, research, data analysis, and coding assistance inside ChatGPT or Codex, the quality improvement is real enough that you’ll notice it within a few sessions. No configuration changes needed.
If you’re evaluating the API for production agent pipelines: wait for independent benchmark results on tool-call reliability before making provider decisions. The token efficiency claim is the most relevant variable for cost-sensitive pipelines — run it against your actual workloads rather than multiplying list prices. OpenAI’s own numbers suggest the efficiency gains can offset the price increase, but that math needs verification on representative tasks, not launch-day benchmarks.
This is the wrong upgrade path if your primary workloads involve complex code review on large repositories, legal or financial document analysis, or multi-agent MCP orchestration. Claude Opus 4.7 holds consistent leads across those categories. The leads are not enormous, but they are consistent enough to be workload-relevant rather than statistical noise.
The Bottom Line
OpenAI shipped a better model. The agentic gains are real. The token efficiency story, if it holds in production, changes the cost math in ways the headline pricing doesn’t capture. The omnimodal architecture is a genuine structural reset after four cycles of iterative refinement on the same weights. The hallucination resistance finding from a major financial institution’s production environment is, if it generalizes, the most commercially significant thing said about GPT-5.5 at launch.
What GPT-5.5 is not is the reinvention the marketing language reaches for. It’s the first genuinely new foundation since GPT-4.5, arriving after a version history that used sequential numbering to describe what was, architecturally, one model refined repeatedly. That baseline reset earns the 5.5 number. It doesn’t earn “new class of intelligence” — a phrase that, deployed at every major model launch, loses meaning faster than context windows gain tokens.
Refinement, executed this well, is legitimately valuable. It’s also just harder to announce. For everything happening across the current AI model landscape as both labs continue shipping — GPT-5.5 earned its number. It just didn’t earn the superlatives.
UP NEXT • DEEP FEED

Best E-Bikes 2026: My Honest Picks After Testing
LOAD MEMORY →

Skip Apple’s $99 iPhone Air Battery—Smarter Buys
LOAD MEMORY →

AI in Manufacturing: Mastering Data for Industry 4.0
LOAD MEMORY →

Best E-Bikes 2026: My Honest Picks After Testing
LOAD MEMORY →Skip Apple’s $99 iPhone Air Battery—Smarter Buys
LOAD MEMORY →AI in Manufacturing: Mastering Data for Industry 4.0
LOAD MEMORY →Related Stories

Musk vs OpenAI Jury Verdict: How a Three-Year Clock Ended a $150 Billion Lawsuit in 90 Minutes
Oura Ring vs AI Sleep Trackers: Which Gives Better Recovery Data?

